
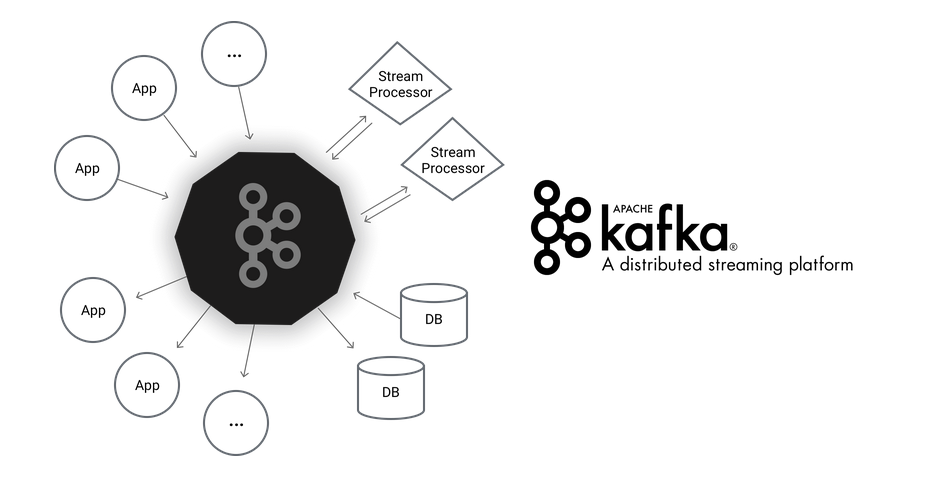
Apache Kafka – A distributed Streaming Platform
Apache Kafka is a distributed publish-subscribe messaging system and a robust queue that can handle a high volume of data and enables you to pass messages from one end-point to another, written in Scala and Java. The project aims to provide a unified, high-throughput, low-latency platform for handling real-time data feeds. Its storage layer is essentially a “massively scalable pub/sub message queue designed as a distributed transaction log,” making it highly valuable for enterprise infrastructures to process streaming data. Kafka is suitable for both offline and online message consumption. Kafka messages are persisted on the disk and replicated within the cluster to prevent data loss. Kafka is built on top of the ZooKeeper synchronization service. It integrates very well with Apache Storm and Spark for real-time streaming data analysis.
Why use Apache Kafka
Following are a few benefits of Kafka −
- Reliability − Kafka is distributed, partitioned, replicated and fault tolerance.
- Scalability − Kafka messaging system scales easily without down time..
- Durability − Kafka uses
Distributed commit log
which means messages persists on disk as fast as possible, hence it is durable.. - Performance − Kafka has high throughput for both publishing and subscribing messages. It maintains stable performance even many TB of messages are stored.
- Kafka is very fast and guarantees zero downtime and zero data loss.
Applications
Kafka can be used in many Use Cases. Some of them are listed below −
- Metrics − Kafka is often used for operational monitoring data. This involves aggregating statistics from distributed applications to produce centralized feeds of operational data.
- Log Aggregation Solution − Kafka can be used across an organization to collect logs from multiple services and make them available in a standard format to multiple con-sumers.
- Stream Processing − Popular frameworks such as Storm and Spark Streaming read data from a topic, processes it, and write processed data to a new topic where it becomes available for users and applications. Kafka’s strong durability is also very useful in the context of stream processing.
About Kafka
A streaming platform has three key capabilities:
- Publish and subscribe to streams of records, similar to a message queue or enterprise messaging system.
- Store streams of records in a fault-tolerant durable way.
- Process streams of records as they occur.
Kafka is generally used for two broad classes of applications:
- Building real-time streaming data pipelines that reliably get data between systems or applications
- Building real-time streaming applications that transform or react to the streams of data
To understand how Kafka does these things, let’s dive in and explore Kafka’s capabilities from the bottom up.
First a few concepts:
- Apache Kafka is run as a cluster on one or more servers that can span multiple datacenters.
- The Apache Kafka cluster stores streams of records in categories called topics.
- Each record consists of a key, a value, and a timestamp.
Kafka has four core APIs:
- The Producer API allows an application to publish a stream of records to one or more Kafka topics.
- The Consumer API allows an application to subscribe to one or more topics and process the stream of records produced to them.
- The Streams API allows an application to act as a stream processor, consuming an input stream from one or more topics and producing an output stream to one or more output topics, effectively transforming the input streams to output streams.
- The Connector API allows building and running reusable producers or consumers that connect Kafka topics to existing applications or data systems. For example, a connector to a relational database might capture every change to a table.

In Apache Kafka the communication between the clients and the servers is done with a simple, high-performance, language agnostic TCP protocol. This protocol is versioned and maintains backwards compatibility with older version. We provide a Java client for Kafka, but clients are available in many languages.
You may like also:
- How To Create Secure MQTT Broker
- How To Enable Free HTTPS on your website
- How To Install Node.js on Ubuntu
- How to install MongoDB in ubuntu
- How to Install InfluxDB on Ubuntu
- What is Jinja



Pingback: Message Brokers : An introduction - Explainer - IoTbyHVM