
Regular LLM vs Reasoning LLM: What’s Actually Different and Why It Matters
There’s a quiet revolution happening in AI right now, and most people don’t even have the vocabulary to describe it yet. When someone says “I use ChatGPT” or “I work with Claude,” they’re usually imagining a single kind of AI — the chatty, responsive, impressively fluent kind that answers your questions in seconds. But behind the scenes, there are now fundamentally two different types of large language models, and they think in completely different ways.
One type responds. The other one thinks.
Understanding the difference isn’t just a nerdy technical exercise. It has real implications for how you use these tools, which one you should reach for on any given task, and where each one is going to let you down. Let’s dig in.
A Quick Primer: What Is a “Regular” LLM Anyway?
When people talk about language models — GPT-4, Claude 3, Gemini 1.5, Llama 3 — they’re usually talking about what we can call standard or “regular” LLMs. These models were trained on enormous amounts of text and learned to predict what word (or token) comes next in a sequence. That sounds deceptively simple, but when you do it at massive scale on basically the entire internet plus libraries’ worth of books and papers, something remarkable happens: the model learns grammar, facts, reasoning patterns, tone, context, and an almost eerie ability to mimic human writing.
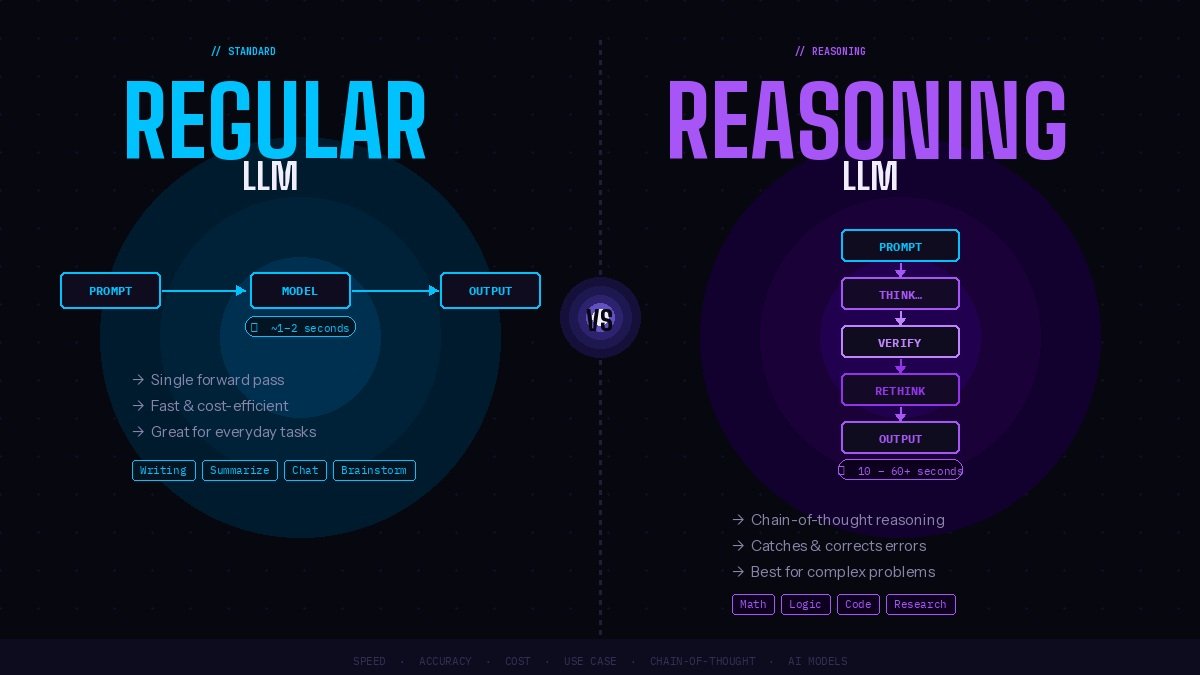
When you ask a regular LLM a question, here’s roughly what happens: your prompt goes in, the model processes it through layers of neural network transformations, and it generates a response token by token — almost like autocomplete, but vastly more sophisticated. The whole thing happens in one forward pass. There’s no separate “thinking” step. The model isn’t working through the problem in stages the way you might on a whiteboard. It’s producing an answer in essentially one fluid motion.
This makes regular LLMs incredibly fast. You type something, you get a response in a second or two. It feels like talking to a very smart person who always knows what to say immediately.
And for most tasks, this works brilliantly. Writing help, summarization, translation, coding assistance, brainstorming, answering factual questions — regular LLMs handle all of this with impressive capability. The speed is a feature, not a bug.
But there’s a category of problems where this approach starts to crack.
Where Regular LLMs Struggle
Ask a regular LLM to write a poem, summarize an article, or explain photosynthesis, and it will do it beautifully. Ask it to solve a multi-step logic puzzle, work through a complex math problem, or plan a software architecture from scratch while juggling a dozen constraints — and you’ll sometimes get confident-sounding answers that are completely wrong.
This isn’t a bug in the traditional sense. It’s a structural limitation. The model wasn’t reasoning through the problem; it was pattern-matching to what looks like a correct answer. If it’s seen many similar problems in training data where a certain approach worked, it’ll confidently apply that approach. But if the problem requires genuine step-by-step deduction — working through a chain of logic where each step depends on the previous one — the single-pass architecture puts a ceiling on how well it can do.
There’s a famous example in the AI research community. If you ask a regular LLM “If a bat and a ball cost $1.10 together, and the bat costs $1.00 more than the ball, how much does the ball cost?”, many models (and many humans, frankly) blurt out “10 cents.” The correct answer is 5 cents. The intuitive answer feels right but is wrong. Getting it right requires slowing down, checking your work, and catching the error in your initial instinct.
Regular LLMs often fail exactly this kind of “slow down and check” test. They’re optimized for fluent, confident response generation — not careful deliberation.
Enter Reasoning LLMs
Reasoning models — the most prominent examples being OpenAI’s o1 and o3 series, DeepSeek R1, and Anthropic’s Claude models with extended thinking — take a fundamentally different approach. Before they give you an answer, they spend time working through the problem in a kind of internal scratchpad. This process is variously called “chain-of-thought reasoning,” “extended thinking,” or simply “the thinking phase,” depending on which model you’re using.
In practical terms, when you submit a hard problem to a reasoning model, there’s a pause — sometimes several seconds, sometimes much longer — where the model is visibly “thinking.” In many interfaces, you can actually watch this process unfold. The model argues with itself, checks its work, backtracks when something doesn’t add up, considers alternative approaches, and eventually arrives at an answer with much more confidence and accuracy.
This is genuinely different from what regular LLMs do. It’s not just generating text that describes reasoning — it’s actually performing intermediate reasoning steps that influence the final output.
The result is a model that performs dramatically better on:
Hard math problems that require multiple steps. Complex logical deductions. Code that involves intricate architecture decisions. Scientific analysis that requires working through competing hypotheses. Any task where getting it right requires checking assumptions and catching errors.
The Architecture Behind the Magic
To understand why reasoning models work better on hard problems, it helps to understand a bit of what’s going on under the hood.
Standard LLMs use what’s called “next-token prediction” in a single forward pass through the network. Think of it like answering a question on an exam without being allowed to use scratch paper — whatever comes to mind first is what you write down.
Reasoning models essentially give the model scratch paper. They’re trained (often using reinforcement learning techniques) to generate internal chains of thought before producing a final answer. This means the computation isn’t compressed into a single pass — it’s spread across many tokens of internal deliberation. More computation per query, more accuracy, more depth.
Some models like OpenAI’s o1 don’t show you this internal thinking process at all — you just see the final answer, delivered more slowly. Others, like Claude with extended thinking enabled or DeepSeek R1, surface the reasoning process so you can see (and verify) the model’s work. The latter is particularly valuable when you need to trust the output — in legal, medical, financial, or technical contexts where knowing how the model got there matters as much as what it concluded.
Speed vs. Depth: The Core Trade-off
Here’s the honest trade-off, because there is one: reasoning models are slower and more expensive to run.
A regular LLM might respond in one to two seconds. A reasoning model working through a complex problem might take 30 seconds, a minute, or even longer. Each of those thinking tokens costs compute, which costs money. And for a lot of everyday tasks, you’re basically paying for horsepower you don’t need — like using a Formula 1 car to drive to the grocery store.
This is why both types of models will continue to coexist. The right tool depends on the task.
For quick lookups, casual conversation, creative writing, first drafts, summarization, and most coding assistance — regular LLMs are faster, cheaper, and perfectly adequate. For proof-writing, competitive programming, advanced mathematical reasoning, scientific research assistance, complex strategic planning, and anywhere that being wrong has serious consequences — reasoning models justify every extra second they take.
Real-World Examples: Where Each Shines
Let’s make this concrete with some side-by-side comparisons.
Scenario 1: Writing a product description
Regular LLM wins here, easily. You need fluent, engaging prose quickly. The task doesn’t require multi-step logic. A reasoning model would produce an equally good result but take three times as long for no additional benefit.
Scenario 2: Debugging a gnarly piece of code
Here it gets interesting. For straightforward syntax errors, a regular LLM is fine. But for deep logical bugs — the kind where a function is technically valid but produces wrong outputs in edge cases because of a subtle interaction between three different components — reasoning models are genuinely better. They’ll trace through execution paths more carefully, catch the edge case, and explain the root cause rather than just proposing surface fixes.
Scenario 3: Solving a competitive math problem
Reasoning models win decisively. This is their native domain. Regular LLMs will often give confident wrong answers to hard math. Reasoning models will work through the algebra step by step, catch their own errors, and arrive at correct solutions at a rate that isn’t even close.
Scenario 4: Brainstorming 20 startup ideas
Regular LLM, no contest. You want fluency, variety, and speed. There’s no “correct answer” to optimize for — you want a broad canvas of ideas to react to. Using a reasoning model here is overkill.
Scenario 5: Analyzing a complex legal contract for hidden risks
Reasoning model. The stakes are high, the document requires careful reading of interdependencies, and missing something could have real consequences. You want the model to work slowly and carefully, not fire off a quick summary.
The “Thinking Out Loud” Factor
One underappreciated advantage of reasoning models — specifically the ones that surface their chain of thought — is interpretability. When a model shows you how it got to an answer, you can actually evaluate whether the reasoning is sound. You can spot where it made an assumption you disagree with. You can catch it if it went down a wrong path before self-correcting. You can learn from its approach to a problem you hadn’t thought through yourself.
With a regular LLM, you get a confident answer and not much else. With a reasoning model that shows its work, you get a collaborator you can actually engage with intellectually. For professionals in fields that require careful thinking — doctors, lawyers, engineers, researchers — this transparency isn’t a nice-to-have. It’s fundamental to whether you can actually trust and use the output.
Are Reasoning Models Always Better?
This is the question everyone wants a clean answer to, and the honest answer is: no, not always — and not even usually, for everyday use.
There are specific failure modes to be aware of. Reasoning models can sometimes “overthink” simple problems — talking themselves into wrong answers on questions that a regular LLM would have gotten right intuitively. They can get trapped in circular reasoning loops. Their thinking traces, while valuable, can also be long and hard to parse when you just need a quick answer.
There’s also the question of creativity. Reasoning models tend to be more analytical and less spontaneous. For tasks where you want unexpected, playful, or emotionally resonant output — fiction writing, marketing copy, poetry — the deliberative nature of reasoning models can actually work against you. The best creative writing often comes from a more fluid, associative process, which is exactly what regular LLMs are good at.
And finally, there’s the user experience angle. Waiting 45 seconds for a response when you’re in a fast-paced work session is genuinely disruptive. Speed matters in practice. The best practitioners learn to read the task and choose the tool accordingly.
Where Things Are Heading
The boundary between these two types of models is already starting to blur. We’re seeing “hybrid” approaches where a model can decide dynamically how much thinking time to allocate based on the difficulty of the question. Ask it something easy, it answers quickly. Ask it something hard, it automatically shifts into extended reasoning mode without you having to configure anything.
This is the direction the industry is moving: models that are not just smart, but metacognitively aware — models that know when they don’t know, that recognize when a problem warrants more careful deliberation, and that can allocate their cognitive resources accordingly. In other words, models that are starting to think about thinking.
We’re also seeing reasoning capabilities get cheaper and faster with each generation. The o1 model from OpenAI that launched in late 2024 was substantially slower and more expensive than today’s options. This gap will continue to shrink. Eventually, the question of “regular vs. reasoning” may become irrelevant because every model will do both seamlessly.
But we’re not there yet. And in the meantime, understanding the difference is genuinely valuable — both for using these tools well today and for making sense of where the whole field is headed.
The Bottom Line
Regular LLMs are fast, fluent, and excellent at the vast majority of everyday tasks. They’re the workhorses — reliable, versatile, and impressively capable for how quickly they respond.
Reasoning LLMs are slower, more deliberate, and dramatically better at hard problems that require careful step-by-step thinking. They’re the specialists — reaching for them when the stakes are high or the problem is genuinely complex is one of the best habits you can develop as an AI power user.
The mental model that works best is this: regular LLMs are brilliant people who always have an answer ready. Reasoning LLMs are brilliant people who pause, take a breath, and work through the problem on paper before speaking. Both are impressive. Both are useful. Knowing which one you need for a given task — that’s the real skill.
The most effective AI users aren’t the ones who use the most powerful model for everything. They’re the ones who know which tool fits the job.


