
Transformers Explained: The Architecture Behind Modern Artificial Intelligence
Transformers are one of the most important breakthroughs in modern artificial intelligence. They revolutionized the way machines process language and led to the development of powerful AI systems such as large language models, AI chatbots, and advanced translation systems.
Before transformers were introduced, natural language processing relied heavily on models such as recurrent neural networks (RNNs) and long short-term memory networks (LSTMs). While these models were useful, they struggled with long sequences of text and required sequential processing, which limited their efficiency.
The introduction of transformer architectures changed the field of AI by allowing models to process entire sequences of data simultaneously and capture long-range relationships in text.
If you want to understand how transformer models fit into the complete AI learning journey, you can explore Complete Roadmap to Learn AI from Zero to LLMs and Generative AI:
https://iotbyhvm.ooo/complete-roadmap-to-learn-ai-from-zero-to-llms-and-generative-ai/
This roadmap explains the progression from programming fundamentals and machine learning to advanced AI technologies such as large language models and generative AI.
What Are Transformers in Artificial Intelligence?
Transformers are a type of deep learning architecture designed to process sequential data such as text.
Unlike earlier models that processed information one word at a time, transformers analyze entire sequences simultaneously. This allows them to capture relationships between words more effectively.
Transformers are especially powerful for tasks involving language because they can understand context across long pieces of text.
Some common applications of transformers include:
- Language translation
- Text summarization
- Question answering
- Conversational AI
- Code generation
Modern AI systems rely heavily on transformer-based architectures.
Why Transformers Were a Breakthrough
Earlier models such as RNNs and LSTMs had several limitations.
These limitations included:
- Difficulty processing long sequences
- Slow training due to sequential processing
- Limited ability to capture long-distance dependencies in text
Transformers solved many of these problems by introducing attention mechanisms that allow models to focus on the most important parts of the input data.
Because transformers process data in parallel rather than sequentially, they can be trained much more efficiently on large datasets.
This breakthrough significantly accelerated the development of modern AI systems.
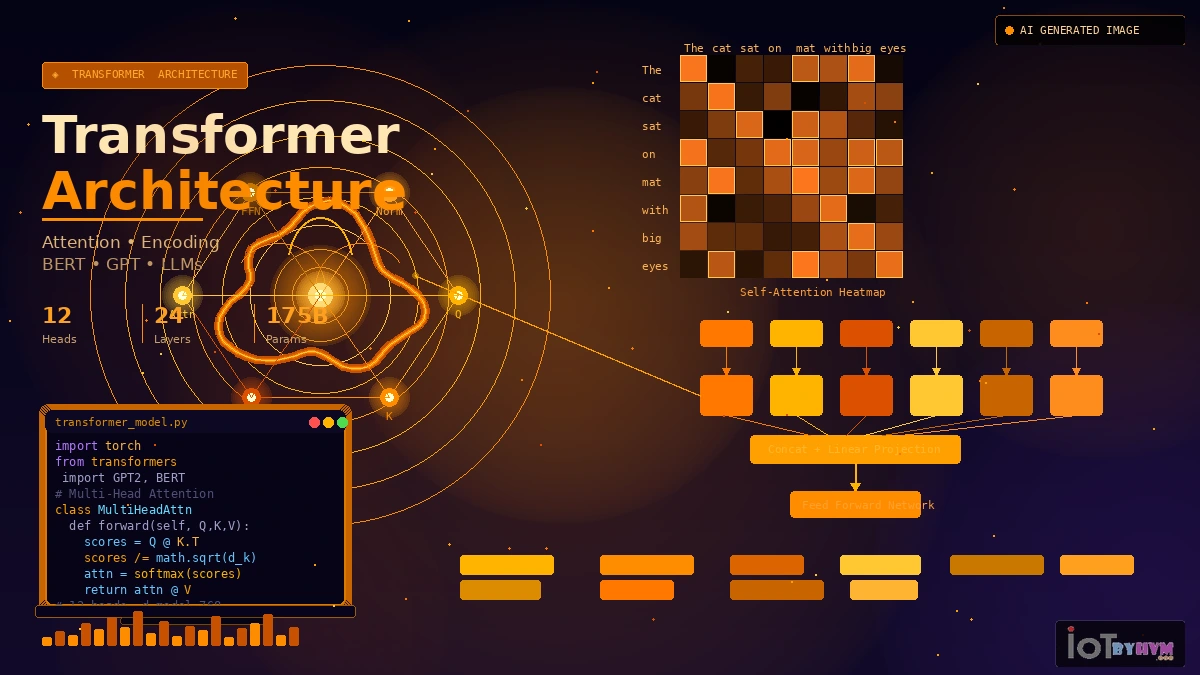
The Attention Mechanism
The most important concept behind transformers is the attention mechanism.
Attention allows a model to determine which parts of the input data are most relevant when making predictions.
For example, when processing a sentence, the model can focus on important words that influence meaning.
Consider the sentence:
“The animal didn’t cross the street because it was too tired.”
In this sentence, the word “it” refers to the animal. Attention mechanisms help models understand these relationships by assigning different levels of importance to different words.
Attention allows models to capture context more effectively than previous architectures.
Self-Attention
Self-attention is a special type of attention used within transformer models.
In self-attention, every word in a sentence compares itself with every other word to determine how strongly they are related.
This allows the model to understand context across the entire sentence.
For example, in the sentence:
“Artificial intelligence is transforming modern technology.”
The model can analyze relationships between words such as:
- artificial
- intelligence
- transforming
- technology
Self-attention helps the model capture these relationships simultaneously.
Encoder–Decoder Architecture
The original transformer architecture consists of two main components:
- Encoder
- Decoder
Encoder
The encoder processes the input sequence and converts it into a numerical representation that captures its meaning.
Multiple encoder layers allow the model to gradually extract deeper contextual information.
Decoder
The decoder generates output based on the encoded representation.
For example, in a translation task, the encoder processes the input sentence in one language, and the decoder generates the translated sentence in another language.
Key Advantages of Transformers
Transformers offer several advantages compared to earlier neural network architectures.
Parallel Processing
Transformers process entire sequences simultaneously, which significantly speeds up training.
Better Context Understanding
Attention mechanisms allow transformers to capture long-range dependencies in text.
Scalability
Transformers can be scaled to extremely large models trained on massive datasets.
This scalability led to the development of modern AI systems such as large language models.
Popular Transformer-Based Models
Many important AI models are based on transformer architectures.
Some well-known examples include:
BERT
BERT (Bidirectional Encoder Representations from Transformers) is designed for understanding language context in both directions.
It is widely used for:
- search engines
- question answering
- text classification
GPT
GPT (Generative Pre-trained Transformer) is designed for generating human-like text.
It powers many AI systems capable of:
- writing articles
- answering questions
- generating code
T5
T5 (Text-to-Text Transfer Transformer) converts many NLP tasks into a unified text-to-text format.
This makes it flexible for a wide range of language tasks.
Applications of Transformer Models
Transformers are used in many modern AI systems, including:
- AI chatbots
- language translation systems
- content generation tools
- speech recognition systems
- document summarization tools
These models have dramatically improved the performance of NLP systems.
Why Transformers Are Important for Modern AI
Transformers form the foundation of today’s most advanced AI technologies.
Large language models, generative AI tools, and many modern AI assistants rely heavily on transformer architectures.
Understanding transformers helps learners grasp how modern AI systems process language and generate meaningful responses.
What Comes After Transformers?
After learning about transformer architectures, the next stage in the AI learning journey focuses on Large Language Models (LLMs).
LLMs are massive AI systems built on transformer architectures that can understand and generate human-like text.
To understand how transformers connect with the full AI learning journey, explore Complete Roadmap to Learn AI from Zero to LLMs and Generative AI:
https://iotbyhvm.ooo/complete-roadmap-to-learn-ai-from-zero-to-llms-and-generative-ai/
This roadmap explains the complete progression from beginner programming skills to advanced AI technologies such as generative AI.


