
GGUF Quantization Explained: What Q4_K_M, Q5_K_S, and Q8_0 Really Mean
You already know:
- Quantization shrinks the model
- GGUF makes it runnable
- 4-bit / 8-bit affect size
But when you download a model, you see scary names:
model.Q4_K_M.gguf
model.Q5_K_S.gguf
model.Q8_0.gguf
These are not random names.
They tell you exactly:
How smart the model will feel
How fast it will run
How much RAM it will use
This is the final layer of understanding local AI.
First: What These Names Represent
A quantized model does two things:
- Compress numbers
- Decide how to reconstruct them during inference
Different methods = different behavior
So quantization types are basically:
Different compression algorithms for the AI brain
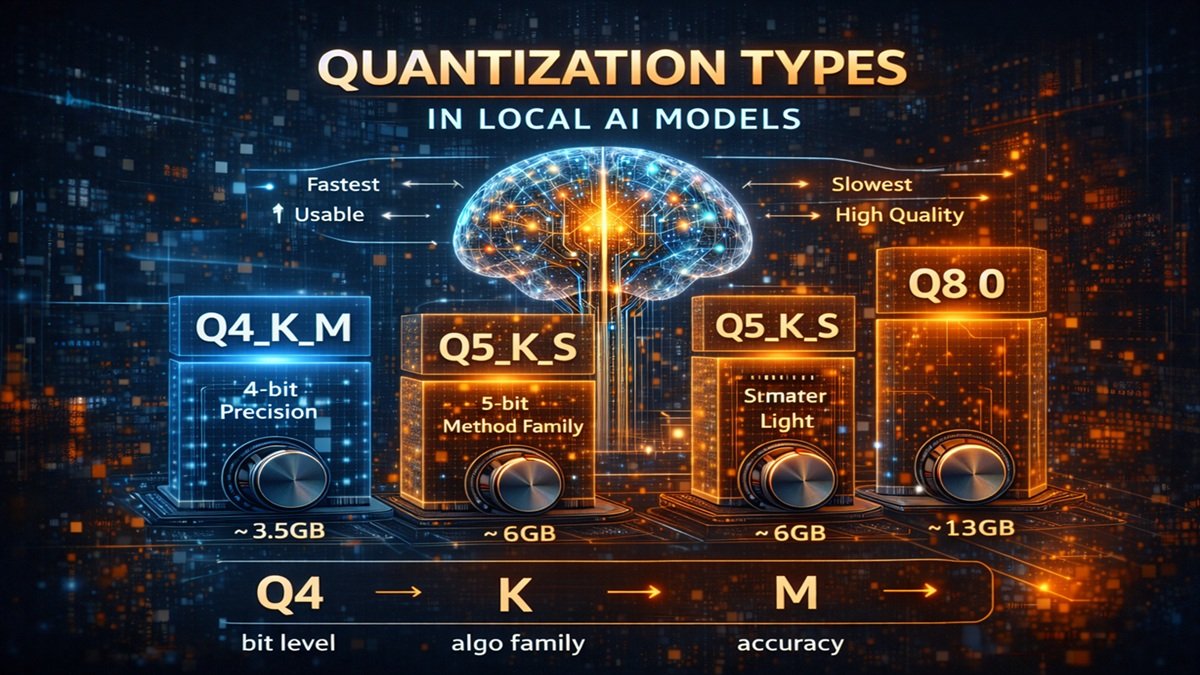
Breaking the Name Format
Take:
Q4_K_M
Split it:
| Part | Meaning |
|---|---|
| Q4 | 4-bit precision |
| K | K-block quantization method |
| M | Medium accuracy variant |
Another:
Q5_K_S
| Part | Meaning |
|---|---|
| Q5 | 5-bit precision |
| K | same family algorithm |
| S | Small size variant |
Another:
Q8_0
| Part | Meaning |
|---|---|
| Q8 | 8-bit precision |
| 0 | Old simple method |
Step 1 — Bit Level (Quality Layer)
This decides the raw intelligence retention.
| Type | Quality | RAM | Speed |
|---|---|---|---|
| Q2 | very bad | ultra small | ultra fast |
| Q3 | weak | tiny | very fast |
| Q4 | good | small | fast |
| Q5 | very good | medium | medium |
| Q6 | excellent | bigger | slower |
| Q8 | near original | big | slow |
So:
More bits = closer to original model brain
Step 2 — Algorithm Family (K vs non-K)
Older quantization (like Q4_0, Q5_0)
→ compresses blindly
K-quantization (Q4_K, Q5_K, etc)
→ compresses intelligently using block statistics
Meaning:
Instead of compressing each number alone,
it compresses groups of neurons together.
So it preserves patterns.
Result:
| Type | Real Behavior |
|---|---|
| Q4_0 | dumb but small |
| Q4_K | much smarter same size |
This is why modern GGUF models almost always use K-quant.
Step 3 — Variant Letters (S, M, L)
These adjust how aggressive compression is.
| Variant | Meaning | Effect |
|---|---|---|
| S | Small | faster, less accurate |
| M | Medium | balanced |
| L | Large | slower, best quality |
So:
Q4_K_S → fastest usable
Q4_K_M → best balance
Q4_K_L → slow but smartest 4bit
The Famous Ones Explained
Q4_K_M (Most Recommended)
Best general local AI format.
- Good reasoning
- Good speed
- Fits in small RAM
This is why almost all Ollama models default to it.
👉 Daily usage sweet spot
Q5_K_S
Higher intelligence but still lightweight.
- Better coding
- Better logic
- Slightly slower
Good for developers.
Q8_0
Almost original model.
- Very accurate
- Heavy RAM
- Slow CPU
Used when quality matters more than speed.
Real Feel Difference
Same model — different quantization:
| Quant | How it feels |
|---|---|
| Q3 | chatbot toy |
| Q4_K_M | usable assistant |
| Q5_K_S | smart helper |
| Q8_0 | near cloud AI |
Model didn’t change.
Only brain precision changed.
Why This Matters More Than Model Size
A 7B Q8 can feel smarter than a 13B Q3.
Because brain clarity > brain size.
So practical performance =
Model Size × Quantization Quality
Not size alone.
Quick Selection Guide
Low RAM laptop (8GB):
→ Q4_K_M
Coding / technical work:
→ Q5_K_M or Q5_K_S
Powerful PC:
→ Q6_K or Q8_0
Fastest chat:
→ Q4_K_S
Final Understanding
Quantization level controls precision of thoughts.
Model size controls capacity of thoughts.
So:
Size = how much the AI can know
Quantization = how clearly it can think
Both together decide real intelligence.
Explore related articles:
- Quantization in AI Models (4-bit, 8-bit, GGUF) — A Clear Detailed Guide
- 7B, 13B, and 70B in AI Models — What “Parameters” Really Mean
- Transformer Architecture in Artificial Intelligence — A Complete Beginner-to-Advanced Guide
- Artificial Intelligence Architectures Explained: From Rule-Based Systems to Transformers and Modern LLMs
- CPU vs GPU: What’s the Difference and Why It Matters for AI, Gaming, and Everyday Computing
- Build Your Own Free Offline AI Chatbot Using Ollama + Open WebUI (Complete Guide)
- Regular LLM vs Reasoning LLM: What’s Actually Different and Why It Matters
- Popular Prompt Frameworks: A Practical Guide to Getting Better Results from AI


