
LM Head in AI: Complete Guide for Deep Learning & LLMs
Introduction
In modern language models, one crucial yet often overlooked component is the LM Head (Language Modeling Head). It is the final layer responsible for converting internal model representations into actual word predictions.
Popular models like GPT (Generative Pre-trained Transformer) and BERT use an LM Head to generate meaningful outputs from learned features.
Read this: Complete Roadmap to Learn AI from Zero to LLMs and Generative AI
What is LM Head?
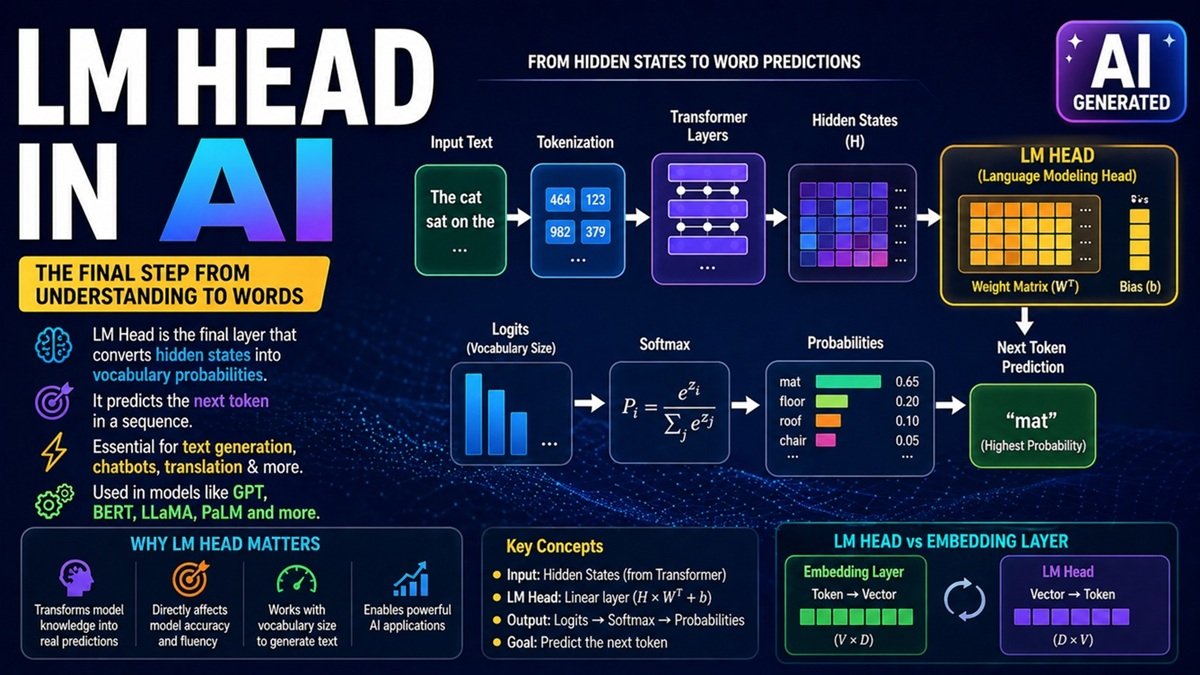
The LM Head is the final projection layer in a language model that maps hidden states to vocabulary probabilities.
In simple terms:
LM Head = “Prediction Layer” that converts model understanding into actual words.
How LM Head Works
Step-by-step process:
- Input text → Tokenized
- Passed through Transformer layers
- Hidden states generated
- LM Head converts hidden states → logits
- Softmax → probabilities
- Highest probability token selected
Mathematical Representation
The LM Head performs a linear transformation:

Where:
- (H) = Hidden state (from transformer)
- (W) = Weight matrix
- (b) = Bias
- Output = Vocabulary-sized vector
LM Head and Vocabulary Connection
The LM Head directly depends on vocabulary size:
- Output dimension = vocab size
- Example:
- Vocab = 50,000
- LM Head output = 50,000 logits
Each logit represents probability for a token.
LM Head vs Embedding Layer
| Feature | Embedding Layer | LM Head |
|---|---|---|
| Purpose | Token → Vector | Vector → Token |
| Position | Input layer | Output layer |
| Shape | V × D | D × V |
Weight Tying (Important Concept)
Modern models often use:
Weight Tying
This means:
- Embedding matrix = LM Head weights (shared)
Benefits:
- Reduces parameters
- Improves performance
- Better generalization
Role in Different Models
GPT Models
- Use LM Head for next token prediction
- Autoregressive generation
BERT
- Uses LM Head for:
- Masked Language Modeling (MLM)
- Predicts missing words
Example of LM Head Output
Input:
"The cat sat on the"
Output logits → probabilities:
| Token | Probability |
|---|---|
| mat | 0.65 |
| floor | 0.20 |
| roof | 0.10 |
| chair | 0.05 |
Softmax Function
Converts logits into probabilities:

Why LM Head is Important
- Converts model knowledge into predictions
- Determines output quality
- Impacts:
- Accuracy
- Fluency
- Token selection
LM Head in Training
During training:
- Model predicts next token
- Loss is calculated (Cross-Entropy)
- LM Head weights updated
Real-World Applications
- Chatbots
- Text generation
- Code generation
- Translation systems
Advanced Concepts
1. Adaptive Softmax
- Efficient for large vocabularies
2. Sparse Output Layers
- Reduces computation
3. Mixture of Softmax
- Improves prediction diversity
Code Example (PyTorch)
import torch
import torch.nn as nn
lm_head = nn.Linear(768, 50000) # hidden_dim → vocab_size
hidden_state = torch.randn(1, 768)
logits = lm_head(hidden_state)
print(logits.shape)
Common Mistakes
- Ignoring vocab size impact
- Confusing embeddings with LM Head
- Not using weight tying
- Misunderstanding logits vs probabilities
Conclusion
The LM Head is the final decision-maker in language models. Without it:
- No predictions
- No text generation
- No AI outputs
It transforms deep learned representations into meaningful language.


