
MHA vs MQA vs GQA: Complete Guide to Attention Mechanisms in Transformers
Introduction
Attention mechanisms are the backbone of modern AI models, especially Transformer-based architectures like GPT (Generative Pre-trained Transformer) and LLaMA.
Among them, three important variants are:
- MHA (Multi-Head Attention)
- MQA (Multi-Query Attention)
- GQA (Grouped Query Attention)
These define how models process and attend to information efficiently—especially critical for speed, memory, and scalability in large language models.
Read this: Vocabulary Size in AI: A Complete Guide for NLP and LLMs
What is Attention in Transformers?
In simple terms:
Attention allows a model to focus on important parts of input while processing text.
It uses three components:
- Query (Q)
- Key (K)
- Value (V)
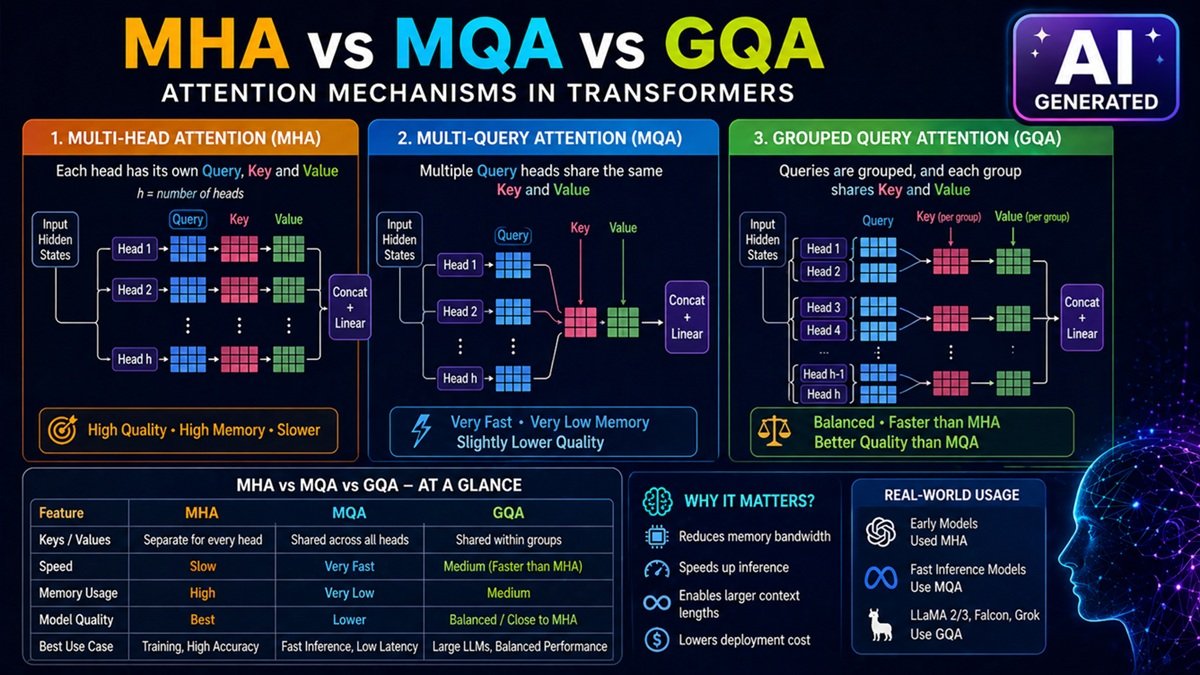
1. Multi-Head Attention (MHA)
What is MHA?
MHA is the original attention mechanism introduced in Transformers.
- Each head has its own:
- Query
- Key
- Value
How It Works
- Input is split into multiple heads
- Each head learns different relationships
- Outputs are combined
Mathematical Form

Pros
- High accuracy
- Rich representation learning
Cons
- High memory usage
- Slower inference
2. Multi-Query Attention (MQA)
What is MQA?
MQA simplifies MHA:
Multiple Query heads share the same Key and Value.
Key Idea
- Separate Q for each head
- Shared K and V across all heads
Benefits
- Much faster inference
- Lower memory usage
- Ideal for deployment
Drawbacks
- Slight drop in quality
- Less expressive than MHA
3. Grouped Query Attention (GQA)
What is GQA?
GQA is a hybrid approach between MHA and MQA.
Queries are grouped, and each group shares Key and Value.
How It Works
- Heads are divided into groups
- Each group shares K and V
- Balance between performance and efficiency
Why GQA?
- Better than MQA in quality
- Faster than MHA
- Used in modern LLMs
MHA vs MQA vs GQA (Comparison Table)
| Feature | MHA | MQA | GQA |
|---|---|---|---|
| Keys/Values | Separate per head | Shared | Shared per group |
| Speed | Slow | Fast | Medium |
| Memory | High | Low | Medium |
| Accuracy | Best | Lower | Balanced |
| Usage | Training | Inference | Modern LLMs |
Real-World Usage
- MHA → Used in early Transformers
- MQA → Used for fast inference systems
- GQA → Used in modern models like LLaMA
Why This Matters in LLMs
As models scale:
- Memory becomes a bottleneck
- Latency matters in real-time apps
These attention variants help optimize:
- GPU usage
- Speed
- Cost
Simple Analogy
Think of attention heads as students:
- MHA → Every student takes full notes individually
- MQA → All students share one notebook
- GQA → Groups of students share notebooks
Read This: Vocabulary Size in AI: A Complete Guide for NLP and LLMs
When to Use What?
- Use MHA → When accuracy is top priority
- Use MQA → When speed is critical
- Use GQA → When you need balance
Advanced Insight (Important)
Modern large models often use:
- GQA + Flash Attention
- KV Cache optimization
These reduce memory bandwidth and improve inference speed drastically.
Common Mistakes
- Assuming MQA is always better (it’s not)
- Ignoring quality trade-offs
- Not understanding KV cache impact
- Confusing heads with dimensions
Conclusion
MHA, MQA, and GQA are not competitors—they are design choices.
- MHA = Accuracy
- MQA = Speed
- GQA = Balance
Understanding these helps you:
- Build efficient LLMs
- Optimize inference
- Scale AI systems


