
Head Dimension in AI: Complete Guide for Transformers
Introduction
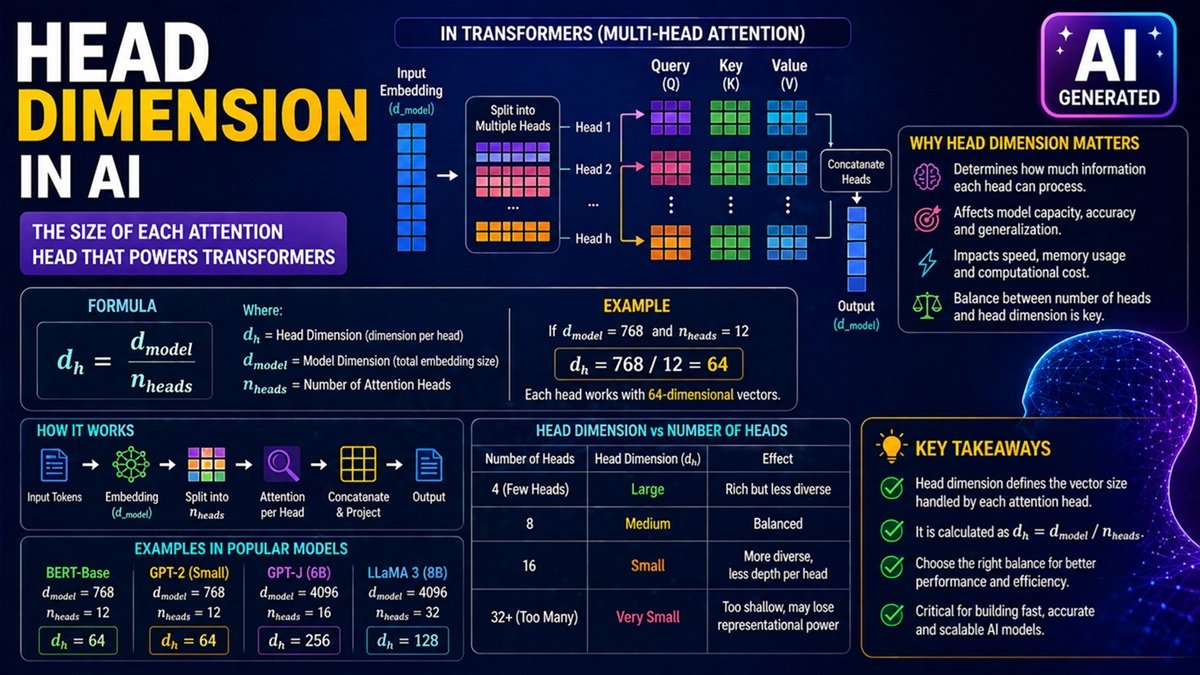
In Transformer-based models like GPT (Generative Pre-trained Transformer) and LLaMA, one important concept that directly affects performance is the head dimension (dₕ).
It plays a crucial role in how attention mechanisms process information across multiple heads.
Read This: TPU vs GPU: Architecture, Working, Differences, and Use Cases in Artificial Intelligence
What is Head Dimension?
Head Dimension (dₕ) is the size of the vector used by each attention head in a Transformer.
In simple terms:
It defines how much information each attention head can process.
Formula for Head Dimension
Head dimension is calculated as:

Where:
- (d_{model}) = Total embedding dimension
- (n_{heads}) = Number of attention heads
- (d_h) = Head dimension
Example
If:
- Model dimension = 768
- Number of heads = 12
Then:

So each head processes a 64-dimensional vector.
Why Head Dimension Matters
1. Information Capacity
- Larger (d_h) → More detailed attention
- Smaller (d_h) → Less expressive
2. Parallel Learning
Multiple heads allow the model to:
- Learn different patterns
- Focus on different relationships
3. Computational Efficiency
- Smaller (d_h) → Faster computation
- Larger (d_h) → More expensive
Relation with Attention Mechanism
Each head computes attention separately:
- Input embedding → Split into heads
- Each head uses dimension (d_h)
- Outputs are combined
Head Dimension vs Number of Heads
| Heads | Head Dim | Effect |
|---|---|---|
| Few heads | Large dₕ | Rich but less diverse |
| Many heads | Small dₕ | Diverse but shallow |
Trade-Off Explained
- Increasing heads → better diversity
- Increasing head dimension → better depth
Balance is key in model design.
Practical Values in Models
| Model | d_model | Heads | dₕ |
|---|---|---|---|
| BERT Base | 768 | 12 | 64 |
| GPT-2 | 768 | 12 | 64 |
| LLaMA | 4096 | 32 | 128 |
Impact on Performance
Larger Head Dimension
- Better contextual understanding
- Higher memory usage
Smaller Head Dimension
- Faster inference
- Lower memory
- May reduce accuracy
Advanced Insight
Modern models optimize head dimension with:
- Grouped Query Attention (GQA)
- Flash Attention
- KV Cache optimization
These techniques help maintain performance while improving speed.
Common Mistakes
- Thinking more heads = always better
- Ignoring relation with (d_{model})
- Using uneven splits (must divide exactly)
- Over-scaling without GPU support
Simple Analogy
Think of attention heads as workers:
- Head dimension = knowledge per worker
- Number of heads = number of workers
You need balance:
- Too many workers with little knowledge → inefficient
- Few workers with too much load → slow
Conclusion
Head dimension is a core design parameter in Transformers:
- Controls information flow per head
- Impacts speed, memory, and accuracy
- Must be balanced with number of heads
Understanding it helps you:
- Design better models
- Optimize training
- Improve inference efficiency


