
Learning Rate in AI/Machine Learning/LLM: A Deep, Practical Guide
Introduction
The learning rate (LR) is one of the most important hyperparameters in machine learning—especially in deep learning. It controls how fast or slow a model learns from data.
If you get the learning rate wrong:
- Too high → training becomes unstable ❌
- Too low → training becomes painfully slow ❌
Get it right:
- Faster convergence
- Better accuracy
- Stable training
What is Learning Rate?
Core Idea
Learning rate defines:
How much the model weights change after each update
During training, models use optimization algorithms like Gradient Descent to minimize loss.
Mathematical View
At each step:

Where:
- θ → model parameters
- η → learning rate
- ∇J(θ) → gradient (direction of change)
👉 Learning rate (η) decides step size in parameter space.
Intuition (Simple Example)
Imagine you are going downhill:
- Large steps → may overshoot valley
- Small steps → slow but safe
Learning rate = step size
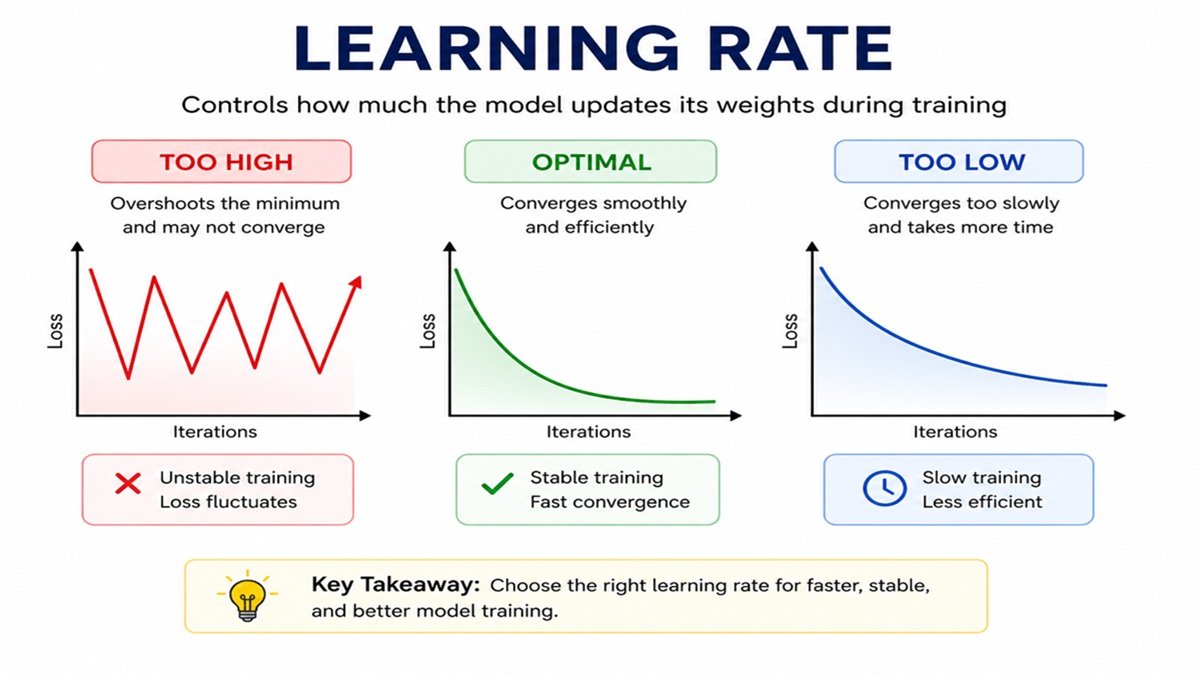
Types of Learning Rate Behavior
1. High Learning Rate
Characteristics:
- Fast updates
- Can overshoot minimum
- Loss fluctuates
Problem:
- Model never converges
2. Low Learning Rate
Characteristics:
- Stable training
- Very slow convergence
Problem:
- Training takes too long
3. Optimal Learning Rate ✅
Characteristics:
- Smooth loss decrease
- Fast convergence
- Stable updates
Learning Rate in Different Optimizers
1. SGD (Stochastic Gradient Descent)
- Simple and effective
- Sensitive to learning rate
2. Adam Optimizer
Adam optimizer
- Adaptive learning rate
- Works well in most cases
- Default LR ≈ 0.001
3. RMSProp
- Adjusts LR per parameter
- Good for RNNs
Learning Rate Scheduling
Instead of fixed LR, we change it over time.
1. Step Decay
Reduce LR after fixed intervals
0.01 → 0.001 → 0.0001
2. Exponential Decay
\eta_t = \eta_0 e^{-kt}
- LR decreases continuously
3. Cosine Annealing
- Smooth cyclic decay
- Helps escape local minima
4. Cyclical Learning Rate (CLR)
- LR increases and decreases periodically
- Helps exploration
5. Warmup Strategy
Start small → increase gradually
Why?
- Prevents unstable early training
Learning Rate in LLM Training
In large models (like LLaMA):
Typical Strategy:
- Warmup (few thousand steps)
- Peak LR
- Gradual decay
Example (LLM Training)
Warmup: 0 → 5e-4
Peak: 5e-4
Decay: → 1e-5
Learning Rate vs Batch Size
Important relationship:
👉 Larger batch size → higher LR possible
Rule of thumb:
LR ∝ Batch Size
Practical Tips (Very Important)
1. Start with defaults
- Adam → 0.001
- LLM → 1e-4 to 5e-4
2. Use LR Finder
- Gradually increase LR
- Find optimal range
3. Watch Loss Curve
- Oscillation → LR too high
- Flat → LR too low
4. Use Scheduler
Never keep LR constant in large models
Advanced Concepts
1. Adaptive Learning Rates
Different LR per parameter:
- Adam
- Adagrad
2. Learning Rate Noise
Adding randomness helps:
- Avoid local minima
3. Second-Order Methods
Use curvature (Hessian):
- More precise updates
- More expensive
Common Mistakes
❌ Too high LR → exploding loss
❌ Too low LR → wasted compute
❌ No scheduler → suboptimal training
❌ Ignoring warmup → unstable start
Visualization Summary
| LR Type | Behavior |
|---|---|
| High | Fast but unstable |
| Low | Stable but slow |
| Optimal | Fast + stable |
Final Intuition
Learning rate is:
“How aggressively your model learns”
Too aggressive → chaos
Too passive → stagnation
Read This: Thinking + Loop in LLMs: A Deep Dive into Reasoning, Iteration, and Agentic Intelligence
Conclusion
Learning rate is the single most impactful hyperparameter in training.
Master it, and you:
- Train faster
- Achieve better accuracy
- Avoid instability


